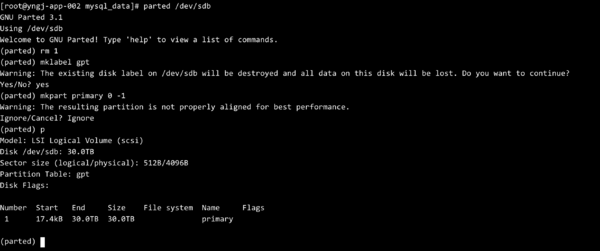
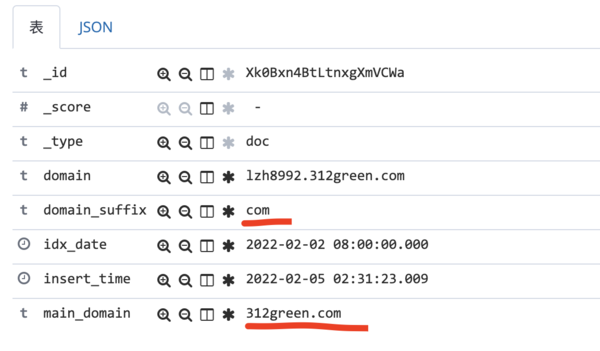
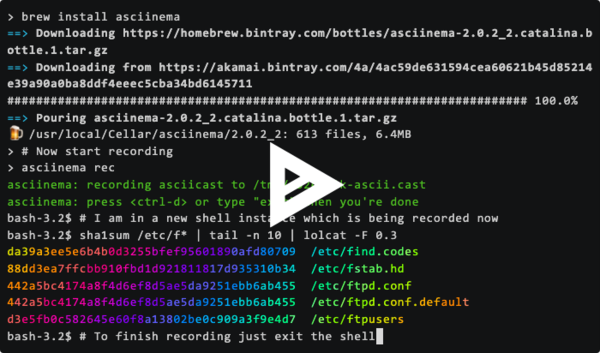
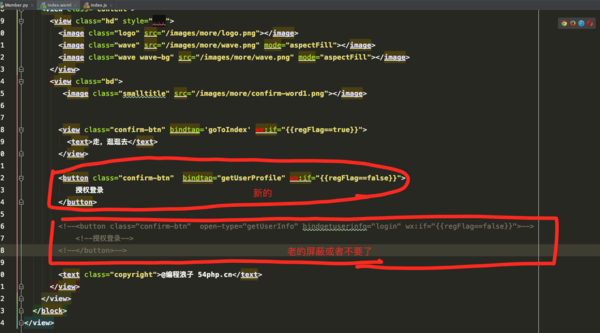
问题 最近我们遇到了一个问题,我们有的Job是常驻的,输出的日志是固定为了,例如如下命令(once.sh 是一个死循环的脚本),这样所有的命令都要输出日志到 notice_wechat.log{ /bin/sh jobs/bin/once.sh notice/wechat ;} >> /data/logs/jobs/notice_wechat.log 2>&1 如果使用默认的logrotate【logrotate基础传送门】的配置,就会重命名然后生产一个新文件,例如 notice_wechat.log_20221020 。但是进程是常驻的,切割之后日志会输出到 notice_we
在工作中会经常对数据库进行运维操作,例如大表清理等等统计数据库占用的空间统计同一个实例下面的所有数据库的容量大小SELECT
table_schema as '数据库',
sum(table_rows) as '记录数',
sum(truncate(data_length/1024/1024, 2)) as '数据容量(MB)',
sum(truncate(index_length/1024/1024, 2)) as '索引容量(MB)',
sum(truncate(DATA_FREE/1024/1024, 2)) as '碎片占用(MB)'
from information_schema.tables
group by table_sch
起因 我在慕课有个flask 入门的课程:点击这里查看慕课课程。当时课程讲解的使用学习的视频网站已经不再提供服务了,为了方便大家学习这里重新找了一个视频源。这里郑重声明:该代码仅用于学习演示,请大家妥善使用,不要给源网站造成任何压力。示例代码新建一个python文件,文件名称是 movie2.py,代码如下# -*- coding: utf-8 -*-
from application import app, db
import requests, os, time, hashlib, json, re
from bs4 import BeautifulSoup
from common.libs.DataHelper&
问题 由于公司使用了OpenVPN来保证网络的安全,但是发现每一次连接上VPN之后整个网络都变成服务器的出口IP了,这时候网络就非常慢了,并且这样也不对,应该需要走OpenVPN的再走。这时候就需要配置分流了。配置在服务端和客户端改一个都可以,由于改服务端影响比较大,所以那就改客户端的配置客户端路由分流路由控制需要由三个参数进行定义:route-nopull如果在客户端配置文件中配route-nopull,openvpn连接后将不会在电脑上添加任何路由,所有流量都将本地转发。vpn_gateway如果在客户端配置文件中配vpn_getaway,默认访问网络不走vpn隧道,如果可以通过添加该参数,下发路由,访问目的网络匹配到会自动进入VPN隧道。route 10.0.0.0 255.255.255.0 vpn_gateway
route 172.
缘由 前面不是写过一个文章 局域网内网机器上网实操。基于这个情况,有时候需要某台机器的文件夹或者文件要被其他机器共享。假设服务器如下服务器名称操作系统IP描述服务器ACentos7.9192.168.1.10文件服务器服务器BCentos7.9192.168.1.11需要访问服务器A的文件技术方案技术方案肯定比较多,例如可以直接 scp 复制服务器A的需要文件到 服务器B。还有一种方式可以共享挂载 :NFSNFS网络文件系统,英文Network File System(NFS),是由SUN公司研制的UNIX表示层协议(presentation layer protocol),能使使用者访问网络上别处的文件就像在使用自己的计算机一样。NFS是基于UDP/IP协议的应用,其实现主要是采用远程过程调用RPC机制,RPC提供了一组与机器、操作系统以及低层传送协议无关的存取远程文件的操作。RPC
缘由 我们有个同事要安装一个软件,就用yum 安装,然后就悲剧。安装完成之后 发现无论执行任何命令都会报错,如下错误psgrep: relocation error: : /usr/lib64/libpthread.so.0: relocation error: symbol __libc_dl_error_tsd, version GLIBC_PRIVATE not defined in file libc.so.6 with link time reference/usr/lib64/libpthread.so.0: symbol __libc_dl_error_tsd, version GLIBC_PRIVAT
缘由 我们有一个产品牵扯到核查数据,在核查数据过程中会发现有一些违规网站,这一些违规网站我们要进行截图保留证据。如果是人工截图就非常麻烦,需要截图之后上传到系统,增加了大家的工作量,我们就想着试着程序自动化截图解决方案 由于我们爬虫都使用的python selenium 调用的chrome无头浏览器,所以我们依然选择了selenium调用chrome进行截图。截图核心代码如下,非常简单###核心代码如下
driver.get( url )
#初始化一个屏幕大小
driver.set_window_size(1400, 900)
##通过脚本获取页面宽和高,设置窗口大小
width = driver.execute_script("return document.documentElement.scrollWidth"
缘由 最近我们一台高防服务器,在同步服务器时间时报 no server suitable for synchronization found,最后经查实是机房屏蔽了udp端口所致,因为ntpdate同步时间使用的是udp123端口。rdate解决方案 既然ntp不行我们改用rdate 完全可以解决因国内一些高防机房屏蔽UDP端口而造成的时间无法同步问题。同时rdate使用的端口是37安装yum install rdate同步安装完成之后可以先手动同步 : /usr/bin/rdate -s time.nist.gov 。最保险的方式是配置定时任务 每10分钟或者半个小时执行一次*/10 * * * * /usr/bin/rd
缘由 目前由于工作需要,我们需要爬虫(本人严重申明:商业爬虫属于违规行为,请各位技术同事不要有意无意的做违规的事情)获取网页一些东西,但是大家都知道目前有很多网站都是用前后端分离的,使用curl请求是没办法获取到页面信息的,所以我们就基于目前我们相对擅长的技术点选择了 “Selenium”。刚好自己又会一点Python。所以这样我们的技术方案就可以执行下去了。Selenium介绍 Selenium 是支持 web 浏览器自动化的一系列工具和库的综合项目。从我个人浅显的理解:提供了扩展来模拟用户与浏览器的交互。有如下特点支持主流的大部分浏览器:ie、ff、safari、opera、chrome支持多平台:windows、linux、MAC 支持主流语言的操作库:Python、Java、C#、Ruby、Jav
起源 最近发下很多人在我的python课程下面提问,关于执行python3.7 安装某些扩展有如下报错ModuleNotFoundError: No module named ‘_ctypes’出现原因 Python3中有个内置模块叫ctypes,它是Python3的外部函数库模块,它提供兼容C语言的数据类型,并通过它调用Linux系统下的共享库(Shared library),此模块需要使用CentOS7系统中外部函数库(Foreign function library)的开发链接库(头文件和链接库)。由于在CentOS7系统中没有安装外部函数库(libffi)的开发链接库软件包,所以在安装pip的时候就报了"ModuleNotFoundError:
起源 最近发下很多人在我的python课程下面提问,关于执行python 定时器Job会报错 如下In aggregated query without GROUP BY, expression #1 of SELECT list contains出现原因 在MySQL5.7.5后,默认开启了ONLY_FULL_GROUP_BY,所以导致了之前的一些SQL无法正常执行,其实,是我们的SQL不规范造成的,因为group by 之后,返回的一些数据是不确定的,所以才会出现这个错误。解决方案 我们知道了原因,就可以去找到对应的解决方法,主要都是修改